In this article we take a look at how the operands of x86 instructions are encoded.
Review
Let’s quickly review information from the earlier x86 addressing article.
x86 instructions vary in the number of operands they take, two operands is fairly common. When two operands are used the following combinations are typically legal, but this varies by instruction.
-
register to register
-
register to memory
-
memory to register
-
immediate to register
-
immediate to memory
Immediate values are are values that follow immediately after the other parts of the instruction. They’re used directly in the computation, for example "add 3 to the eax register", 3 is an immediate value.
When an instruction refers to a memory location there are different ways to provide the address, called addressing modes. Most if not all CISC-style (like x86) processors provide multiple addressing modes.
Some addressing modes for 16-bit and 32-bit code are:
- reg
-
the register contains the address,
- reg + reg
-
add the two registers together to calculate the address,
- disp16/32
-
a 16 or 32-bit displacement, in this case it just serves as an absolute address.
- reg + disp8/16/32
-
a register plus an 8, 16 or 32-bit displacement.
- reg + reg + disp8/16
-
add the two registers together, plus a a 8 or 16bit displacement to cacluate the address.
- reg + reg*scale + disp8/32
-
scale is either 1, 2, 4 or 8. Introduced with the 386 in 32-bit mode.
Which modes are available depends on the mode of the processor, the width of data the instruction is operating on and which registers are used.
Under the hood
x86 instruction encoding is very detailed, with many exceptions. Here’s a quick overview.
In Figure 1 we can see the fields that might be present in an x86 instruction. The Prefix, ModR/M, SIB, Displacement and Immediate fields are all optional. The longest possible instruction is 15 bytes, I seem to remember that you can write a longer instruction that seems valid, but processors will refuse to understand it. I couldn’t possibly cover all of this, it wouldn’t fit in a blog post and I’m not sure I’ll ever know all the details. However I’d like to share a taste of this.
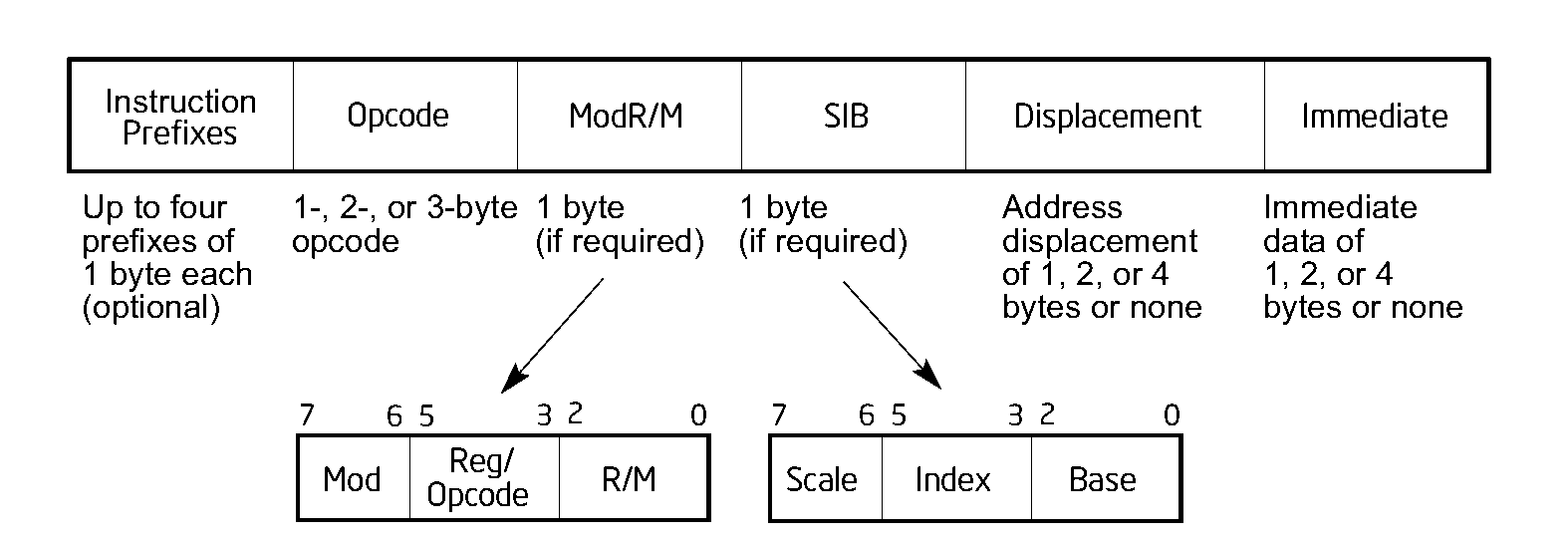
Zero operands
This case is simple, the instruction won’t have a ModR/M byte, SIB byte, displacement or immediate.
One operand
Instructions such as bswap will use the lower three bits of their opcode to indicate the single register argument (and do not support operation on memory locations).
When a single operand instruction can access memory (such as inc) then a ModR/M byte is used. The Mod and R/M fields are used, and the Reg/Opcode fields may be used to extend the opcode (in the case of inc these bits should be zeros). inc is also available as a single byte, encoding the register in the opcode field.
Some instructions will have particular opcodes that hard-code the register to use. For example add has some encodings that use eax. These alternative encodings allow shorter instruction lengths, and we know that Packing more instructions into fewer bytes can be faster.
Two operands
An instruction with two operands typically has a Mod/RM byte. This enables register-memory and memory-register operations, a flag within the opcode byte indicates the direction (register-memory or memory-register). Both operands are encoded in the ModR/M byte, one is in the Reg field (and msut be a register) and the other is in the Mod and R/M fields. Which may be a register (Mod = 11) or a memory location (Mod selects if a displacement is used for example). R/M selects the register to use (either directly or as the base for a memory computation). There are 3 bits and 8 32-bit registers, however since esp cannot be used in a memory operand the bit pattern 100 means that a SIB byte will follow the ModR/M byte.
In 16-bit instructions (not necessarily 16-bit mode, but an instruction that operates on 16-bit values) these R/M bits are interpreted differently and enable access combinations of two registers.
When a SIB byte is present it provides the more complex addressing modes that take a scale, an index and a base. If the Index field has the bit pattern 100 it means there is no index*scale component (esp cannot be used as an index), and when base is 101 the behaviour depends on the Mod field. These combinations allow for a couple of different addressing modes with optional bases, indexes and displacements, and even allow the ebp register to be used as a base which it could not before the SIB byte was added (prior to 386, although that was just the bp register, don’t @-me!).
Two operand instructions can also involve immediate values. For example the add instruction can use the ModR/M fields (not the reg field) and an immediate value.
64-bit
amd64 added 8 new general purpose registers, now rather than 3 bits required to represent a register, we need to add a fourth bit. To add this to the ModR/M and SIB bytes a prefix byte is added to the front of the instruction, prefix bytes already exist for specifying repeated instructions or bus-locked instructions, think of them as additional opcodes. Some bits within the new prefix byte are used to extend the Reg, R/M, Index and Base fields. If no prefix byte is used then its implied that these bits are zero and the eight x86 registers may be used.
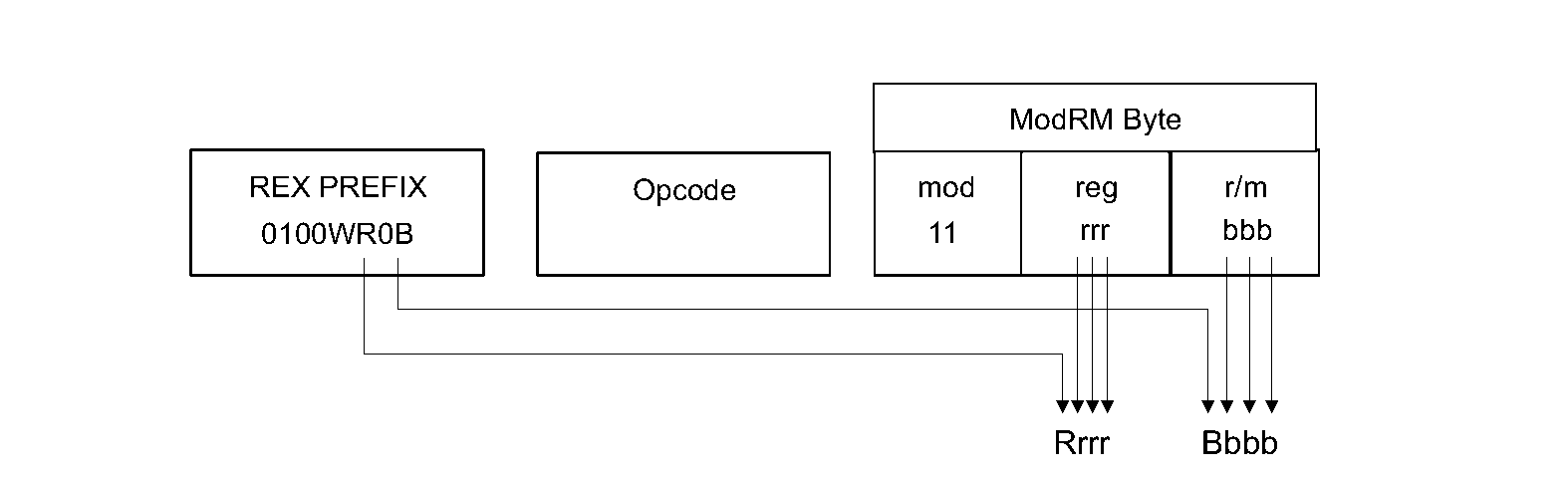
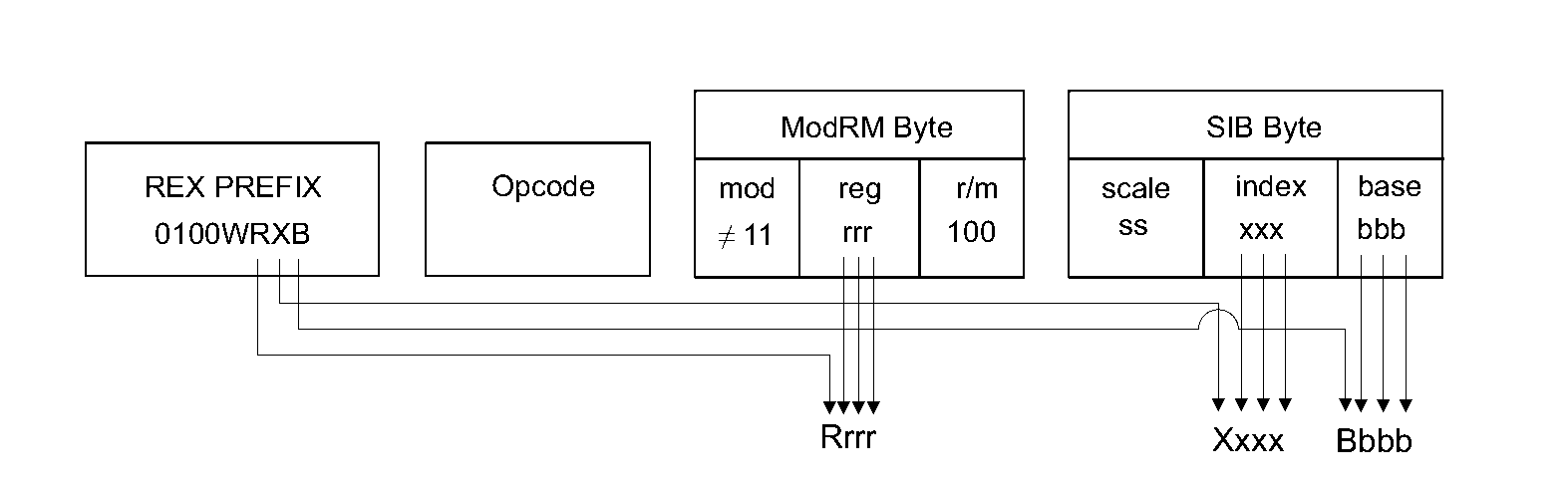
amd64 also added moffset addressing. Four specific opcodes used for mov allow use of a 64-bit immediate value to be used as a memory location, it is not used in an address computation like the other addressing modes.
Finally amd64 also added RIP-relative addressing for non jump instructions. These are specific bit patterns in the ModR/M and SIB bytes that say the displacement following the instruction should be added to the value of the rip register (the instruction pointer) as it would be after this instruction. This can make it easier to address data in a position independent code fashion, making dynamic linking and address space layout randomisation easier.
More encodings
Some instructions can use up to four operands, I see it there in the manual but I’ve never needed to learn this.
Likewise I’ve only briefly looked at floating point and vector instructions, not enough to begin to look at their operand encodings.
The point of this article
Mostly this article is just me learning about these details and being interested in how something such as register choice can affect instruction length.
If there’s a message to take away it’s that the x86, having evolved from the 8086 through to the multicore, speculative, processors we have today is very complex. This complexity has engineering, silicon and power-usage costs, and while there are benefits in backward compatibility, particularly for business reasons, there are drawbacks and they have a tendency to compound upon one another.